Crowlang symbol table design
So whilst working on my symbol table design for Crowlang I was facing a heft design problem. You see usually when compilers deal with name lookups/variable references they use something called a symbol table. This symbol table is a data structure that allows you to lookup any alias, enum, struct, class function or variable in usually a module. This is useful for performing type checking across modules as well as within a module.
So I have a strong desire like other modern programming languages to have my language be order independt on the module-/top-level (like Rust, Golang, Nim, etc). So in order to this you need to have a preconstructed symbol table. And I actually wrote basic/naive implementation of my symbol table which allows you to quickly search up the semantic type information for a symbol (a software entity with a name).
And this all worked fancy/dandy for my source to source compiling from my programming language to C++. As I had done the semantic analysis ahead of time I could carelessly generate the C++ code and just compile it.
But this changes when you start working on IR generation. And since I had a strong desire to have a backend which generates C++ code as well as use LLVM IR. I started to face some problems.
You see I wanted to have a mid level IR (MIR). Which the C++ backend could fallback on if the AST was not enough for code generation.
So when I started to tackle an IR builder of some sorts.
Now after a couple of days of programming.
I ran into a troubling issue, "how do I resolve a function call?".
You see my call instruction, requires a pointer to a function (I could use a string and resolve it later but this seemed not robust).
You see without a dedicated symbol table, for IR generation how would I be able to perform a lookup for a previously defined function and link the function for the call instruction properly.
So I quickly realized, I will need multiple symbol tables:
- One for semantic analysis step, which stores symbol related type information (
SymbolData). - One for the MIR generation step, which holds references to different IR Functions, IR instructions, and other IR related components for lookup and resolution.
- Another one possibly for the LLVM IR generation step.
- And then another one for possibly resolving macros/AST nodes (no clue how hygienic macros should be implemented yet).
So I thought to myself, "Hey regenerating the symbol table up to 4 times sounds terribly inefficient.". You see in order to generate a symbol table, I need to walk my AST using a visitor pattern. Which painstakingly traverses every AST node in the program and then creates a nested structure. Of symbol names/identifiers which have some kind of relevant data attached (depends on the compiler step). As well as optionally have a scope, in which you can search for more symbols.
Here is a pseudo JSON example:
{
id: PrintMsg
scope: { id_data: ..., optional_nested_scope: {...} }
}
So some naive approaches to tackle this problem could be:
- Define a new
SymbolTableclass everytime the need for a new one arises. - Store all the needed information for all compiler steps into a single
SymbolTable.
Both these solutions would not suffice as.
For solution 1. we would need to regnerate the tree structure everytime from the AST for the construction of each new SymbolTable.
For solution 2. would be terribly memory inefficient as well, as we have ton of memory intensive data structures.
Contained in our single SymbolTable instance.
That we might not even use depending on the compiler pass (violating Single Responsibility Principle).
So we need to find a way to decouple, the nested structure of the symbol table from the data it references. In order to do this we need to two new classes/concepts.
One is a SymbolTree class which will store the nested structure of our symbols.
And the second one is a SymbolRegister<T> class.
The lookup into the SymbolTree will give back a SymbolId (basically an integer).
Which can be used to lookup a value in a SymbolRegister<T> (where T is a template and can be any type).
This way the nested structure of the SymbolTree does not need to be reconstructed.
Instead what you do is you specialize SymbolRegister<T> for the use case you want.
All you need to do then is insert the right data for the right SymbolId's.
So you might ask yourself now, "But dont you need to re-walk the AST for the construction of every SymbolRegister<T>".
In order to efficiently prevent this what I can do is create a first initial specialization for SymbolRegister<AstNode*>.
Since most SymbolRegister<T> implementations I will be using are constructed from the AST.
I can instead directly walk through a SymbolRegister<AstNode*>, and generate any new SymbolRegister<T>'s by walking through this type.
So I dont even need to traverse the AST in full anymore.
Now this is all very complex (but believe me this is necessary, as Rust uses a similar nested structure to id register concept for its symbol table).
But when this is all said and done I only need to generate a single SymbolTree and then I can create a SymbolTable<T> type.
Which references the single SymbolTree and contains operations for directly resolving the SymbolTree to a value in its specialized SymbolRegister<T>.
This is a lot of words, but a simple UML diagram will clarify this.
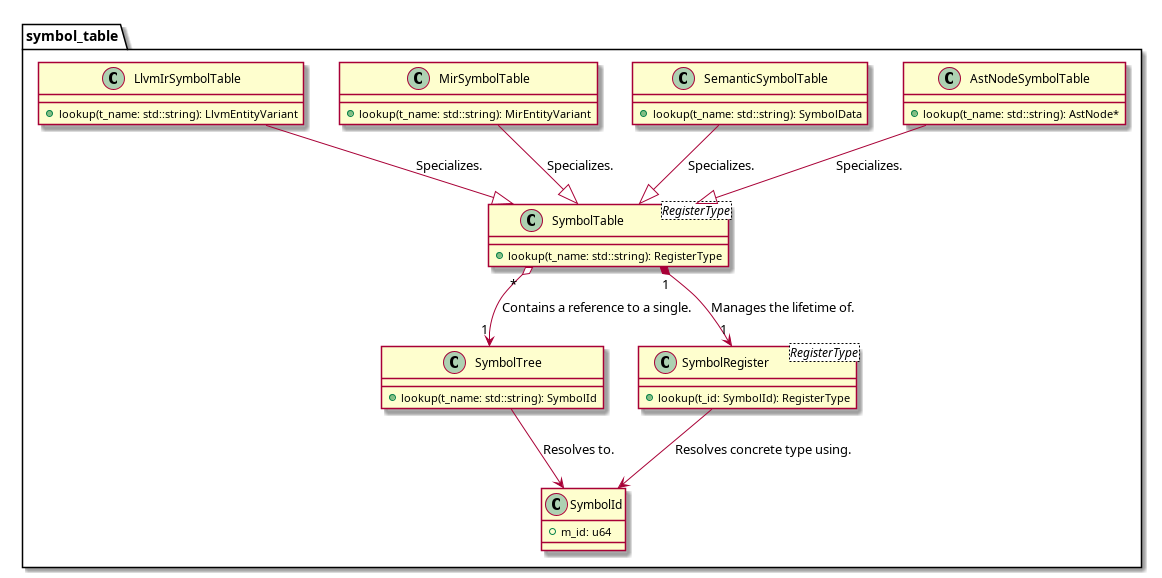
Now the issue is how do I generate this kind of complex object relational type?
In order to do so, I need to create a SymbolTreeFactory for creating the nested structure of the SymbolTree.
... Figure this shit out ...
And then a SymbolTableFactory, which will take the `